Apache Ranger
介绍¶
Apache ranger是一个Hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的Hadoop生态圈的所有数据权限。
Apache Ranger可以对Hadoop生态的组件如Hive,Hbase进行细粒度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问HDFS文件夹、HDFS文件、数据库、表、字段权限。这些策略可以为不同的用户和组来设置,同时权限可与hadoop无缝对接。
支持组件:
- Apache Hadoop HDFS
- Apache Hive
- Apache HBase
- Apache Storm
- Apache Solr
- Apache Kafka
- YARN
- ZK
- KNOX
项目地址
工作原理¶
Kerberos只是控制集群的登录,相当于一把钥匙打开了进入集群操作的大门,并没有实现用户操作权限的管理,因此我们引入Ranger做权限管理。
Ranger提供一个集中式安全管理框架,它可以对Hadoop生态的组件如HDFS、Yarn、Hive、HBase等进行细粒度的数据访问控制,基本覆盖现有技术栈的组件。通过操作Ranger控制台和REST API,可以轻松的通过配置策略来控制用户访问权限。
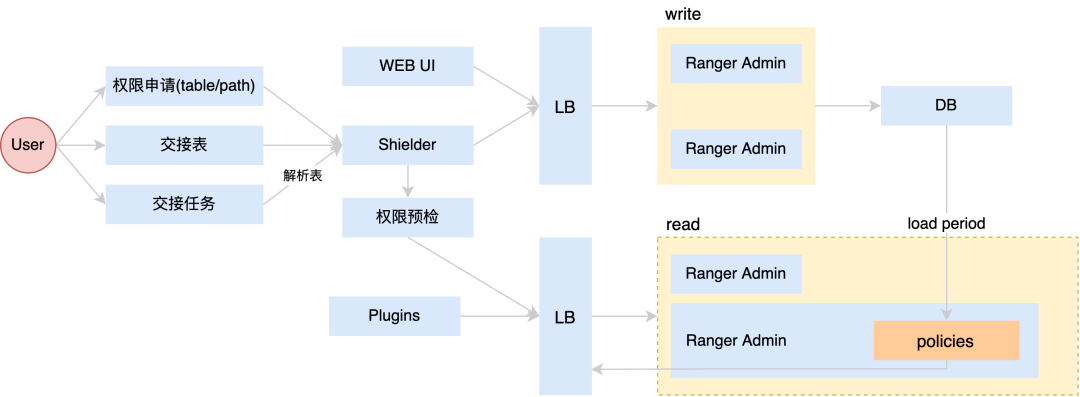
我们使用的Ranger是基于1.2.0版本改造的,部署了2台写节点和2台读节点并接入公司的负载均衡系统来实现读写分离,用户在申请Hive表或者HDFS path,交接表或者交接任务时,会发送请求给Shielder(Shielder是工具侧的授权服务),授权时接入写节点的LB,shielder会通过LB调用Ranger Admin的REST API进行权限操作,Ranger Admin将相关policy持久化到DB,赋权完成后Shielder还会通过LB调用读节点的REST API进行权限预检,预检通过后用户申请权限的流程就结束了。
读节点的Ranger Admin会定时的从DB中全量load policy,plugins在poll policy时,Ranger Admin会将内存中的policy返回给嵌入在各个大数据组件的plugins。
HDFS Path鉴权¶
授权接口的改造¶
原生的Ranger授权接口需要传入RangerPolicy,对于工具层需要给HDFS表路径或者非表路径授权比较繁琐,因此我们改造了授权接口,只需要传入四个参数,如下:
-
service : ranger service name,用于识别service
-
type:path或者table,用于识别是为表赋权还是为路径赋权
-
resources:具体的HDFS路径或者Hive表
-
access:具体的权限类型,read或者write
如果type是table,会根据resources中的table,通过Hive Metastore(HMS) client获取table location,再根据路径查找相关policy是否存在来决定是更新还是创建。