author: moses creation date: 2022-08-16 10:40 modification date: 星期二 16日 八月 2022 10:40:50 aliases: 大数据技术框架学习 description: tags: 大数据 实时计算 离线计算
学习方法: 我是谁? 我来自哪里? 我要去往何处? 它是什么及它的发展历程和特点(介绍)?为什么是它有什么作用(对比总结)? 如何使用它(案例演示)?它有什么不足?(分析思考)
大数据体系学习¶
数据采集技术框架¶
数据采集也被称为数据同步。
随着互联网、移动互联网、物联网等技术的兴起,产生了海量数据。这些数据散落在各个地方,我们需要将这些数据融合到一起,然后从这些海量数据中计算出一些有价值的内容。此时第一步需要做的是把数据采集过来。数据采集是大数据的基础,没有数据采集,何谈大数据! 数据采集技术框架包括以几种:
日志数据实时监控采集¶
- Flume
- Logstash
- FileBeta
技术对比¶
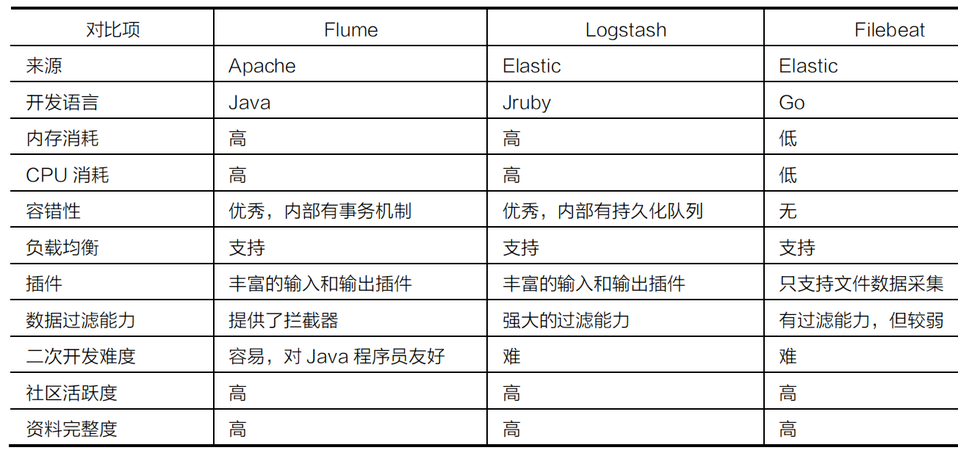
技术选型¶
- Flume:如果采集场景多变
- Logstash:如果在ELK架构中
- FileBeta:如果采集场景单一,为了追求性能
关系型数据库离线数据采集¶
- Sqoop:Sqoop)是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中.Sqoop安装 - Sqoop教程
- Datax:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
- kettle:Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
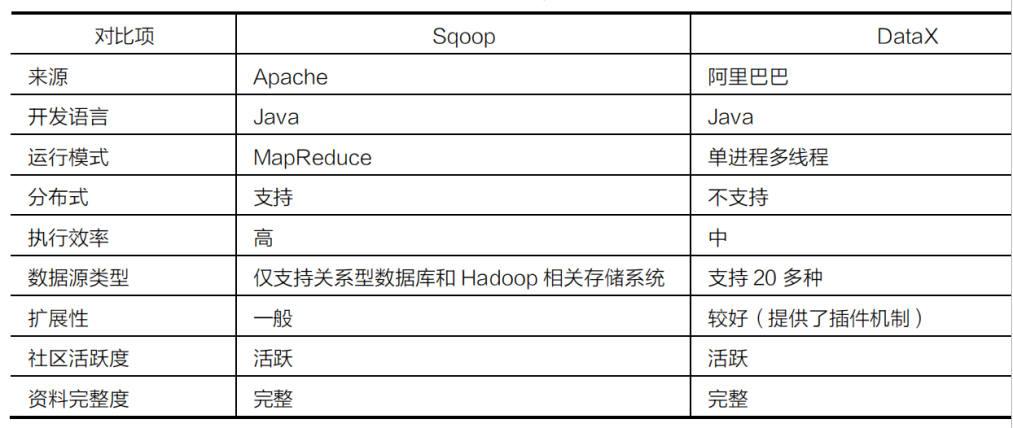
技术对比Sqoop VS Datax¶
技术对比Sqoop VS Kettle¶
| 对比项 | Kettle | Sqoop1 |
|---|---|---|
| 适用场景 | 数据ETL,简单或复杂的数据抽取、数据转换、数据清洗、数据过滤、数据同步。 | |
| 支持丰富的数据源和数据输出形式,适用于多种数据源之间数据同步,大数据清洗转换处理 | 仅适用于关系型数据库与大数据平台之间数据迁移同步 | |
| 支持系统 | Linux、Windows | Linux |
| 学习资源 | 丰富,有中文社区,功能多知识点多 | 一般,因功能少知识量少,学习资料重复率高 |
| 部署难度 | 一般,需独立部署,有一些配置 | 简单,在CDH、Ambari HDP添加sqoop服务,可视化界面操作 |
| 大数据平台集成 | 不支持 | CDH、Ambari HDP均支持集成sqoop1.4.7 |
| 依赖性 | 独立部署运行,不依赖第三方软件 | 依赖大数据平台CDH或HDP |
| 集群 | 支持 | 支持 |
| 使用难度 | 一般,可视化界面操作,入门简单。需要一月左右时间才能深入熟悉和掌握大部分功能 | 简单,只需熟悉sqoop命令 |
| 可视化界面 | 支持,可在spoon界面上操作 | 不支持,只能通过后台命令操作 |
| 扩展性 | 扩展性很强,可自定义Java代码或sql脚本处理 | 不支持 |
| 研发工作量 | 较大 | 一般 |
| 定时任务 | 支持,自带定时任务功能较弱,可独立部署web服务由xxl-job等定时任务远程调度执行 | 本身不支持,可借助xxl-job等定时任务远程调度命令脚本执行 |
| 增量同步 | 有条件支持,需自定义增量同步策略 | 有条件支持,需自定义增量字段last-value值,只能手工操作执行 |
| 数据清洗处理 | 支持 | 不支持 |
| Atlas支持 | 不支持 | 支持 |
| 安全性 | 密码加密、访问可授权,不支持kerberos和ranger | 不支持密码加密,支持kerberos认证,ranger权限管理 |
| 性能 | 性能较强,单机同步性能可达到每秒十万条以上 | 千万级以下小数据量性能较差,亿级以上大数据同步性能较好 |
| 优点 | 功能强大、支持丰富的数据源和数据输出形式,扩展性强,有可视化图形开发界面,入门容易,性能较强 | 在大数据平台上部署简单,亿级以上大数据同步性能较好 |
| 缺点 | 软件包比较大,开发工作量大 | 无界面,只能通过命令行脚本操作,不支持扩展开发,功能少,不支持数据清洗处理 |
| 数据源-关系型数据库 | 支持绝大部分关系型数据库 | 支持MySQL、Oracle等主流关系型数据库 |
| 数据源-文件 | 支持多种文件格式导入 | 不支持 |
| 数据源-非关系型数据库 | 支持多种非关系型数据库 | 不支持 |
| 数据源-HTTP接口消息 | 支持 | 不支持 |
| 数据源-大数据存储 | 支持 | 仅支持从大数据存储HDFS导出文本文件(可以是hive表数据文件)到关系型数据库 |
| 数据源-流 | 支持kafka、JMS、MQTT | 不支持 |
| 数据输出-关系型数据库 | 支持绝大部分关系型数据库 | 支持MySQL、Oracle等主流关系型数据库 |
| 数据输出-文件 | 支持多种文件格式导入 | 不支持 |
| 数据输出-非关系型数据库 | 支持多种非关系型数据库 | 不支持 |
| 数据输出-Web接口消息 | 支持 | 不支持 |
| 数据输出-大数据存储 | 支持多种大数据存储 | 支持HDFS、Hive、HBASE、accumulo、hcatalog大数据存储 |
| 数据输出-流 | 支持kafka、JMS、MQTT | 不支持 |
技术选型¶
- Sqoop:如果只需要实现MySQL和HDFS之间的数据转移,使用Sqoop会更加轻量
- Datax:如果要实现多种数据源之间的数据转换,建议优先考虑DataX
关系型数据库实时数据采集¶
- Cannal:Cannalcanal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据实时订阅和消费,目前主要支持了MySQL,也支持mariaDB。
- Maxwell:Maxwell是一个能实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。它的常见应用场景有ETL、维护缓存、收集表级别的dml指标、增量到搜索引擎、数据分区迁移、切库binlog回滚方案等。
- Streamsets:Portal - StreamSets Docs一个大数据实时采集ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度。
技术对比¶
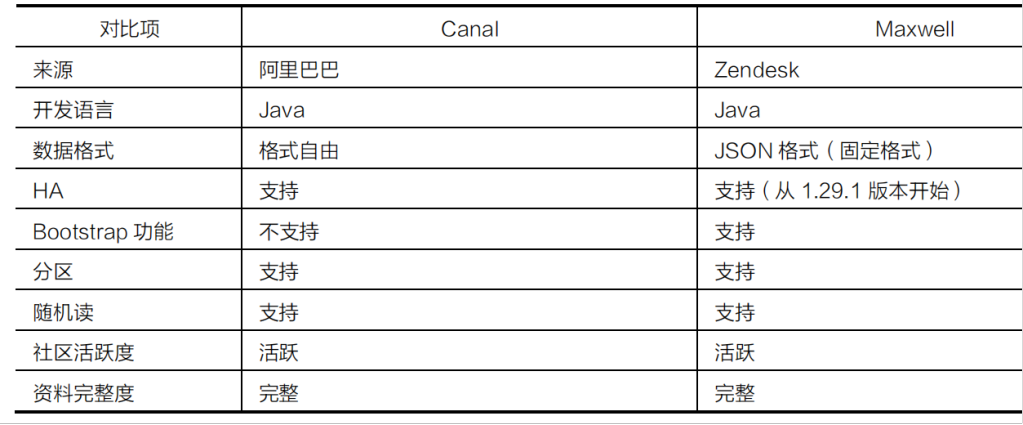
技术选型¶
- Cannal:如果要封装一套稳定可靠且长期使用的平台,
- Maxwell:如果基于MySQL和Kafka的技术栈,短时间内需要快速迭代,推荐使用更加轻量级的Maxwell
数据存储技术框架¶
数据的快速增长推动了技术的发展,涌现出了一批优秀的、支持分布式的存储系统。
数据存储技术框架包括HDFS、HBase、Kudu、Kafka等。
- HDFS它可以解决海量数据存储的问题,但是其最大的缺点是不支持单条数据的修改操作,因为它毕竟不是数据库。
-
HBase是一个基于HDFS的分布式NoSQL数据库。这意味着,HBase可以利用HDFS的海量数据存储能力,并支持修改操作。但HBase并不是关系型数据库,所以它无法支持传统的SQL语法。
-
Kudu是介于HDFS和HBase之间的技术组件,既支持数据修改,也支持基于SQL的数据分析功能;目前Kudu的定位比较尴尬,属于一个折中的方案,在实际工作中应用有限。
-
Kafka常用于海量数据的临时缓冲存储,对外提供高吞吐量的读写能力。
分布式资源管理框架¶
- yarn
- k8s
- openstack
- Mesos
数据计算技术框架¶
离线计算¶
-
MapReduce可以称得上是大数据行业的第一代离线数据计算引擎,主要用于解决大规模数据集的分布式并行计算。MapReduce计算引擎的核心思想是,将计算逻辑抽象成Map和Reduce两个阶段进行处理。
-
Tez计算引擎在大数据技术生态圈中的存在感较弱,实际工作中很少会单独使用Tez去开发计算程序。
-
Spark最大的特点就是内存计算:任务执行阶段的中间结果全部被放在内存中,不需要读写磁盘,极大地提高了数据的计算性能。Spark提供了大量高阶函数(也可以称之为算子),可以实现各种复杂逻辑的迭代计算,非常适合应用在海量数据的快速且复杂计算需求中。
实时计算¶
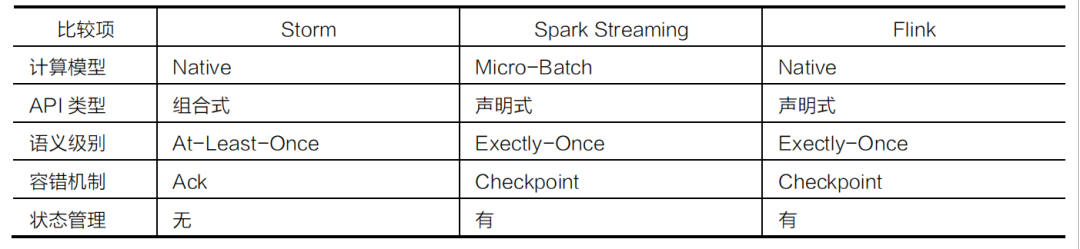
-
Storm主要用于实现实时数据分布式计算。
-
Flink属于新一代实时数据分布式计算引擎,其计算性能和生态圈都优于Storm。
-
Spark中的SparkStreaming组件也可以提供基于秒级别的实时数据分布式计算功能。
技术对比¶
数据分析技术框架¶
离线OLAP数据分析引擎¶
-
Hive的执行效率一般,但是稳定性极高;
-
Impala基于内存可以提供优秀的执行效率,但是稳定性一般;
-
Kylin通过预计算可以提供PB级别数据毫秒级响应。
技术对比¶

实时OLAP数据分析引擎¶
-
Druid和Doris是可以支持高并发的,ClickHouse的并发能力有限;Druid中的SQL支持是有限的,ClickHouse支持非标准SQL,Doris支持标准SQL,对SQL支持比较好。
-
Druid和ClickHouse的成熟程度目前相对比较高,Doris处于快速发展阶段。
技术对比¶

任务调度技术框架¶
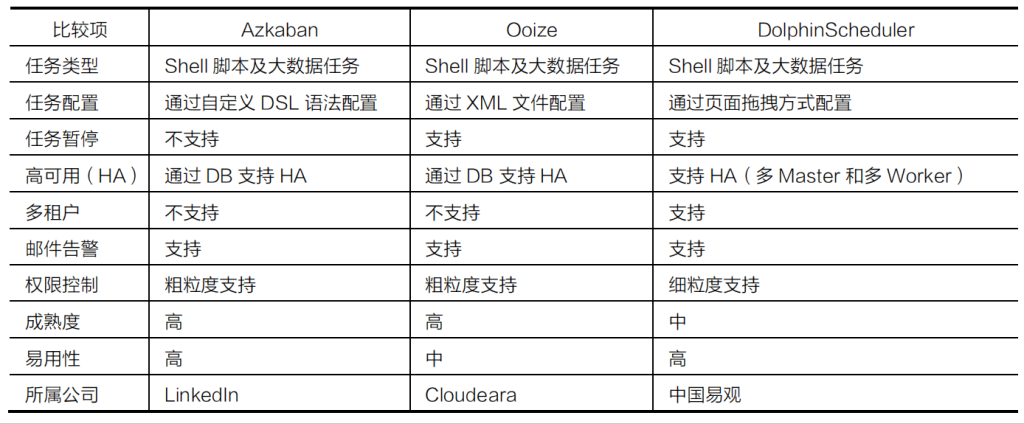
大数据底层基础技术框架¶
Zookeepe主要提供常用的基础功能(例如:命名空间、配置服务等),大数据生态圈中的Hadoop(HA)、HBase、Kafka等技术组件的运行都会用到Zookeeper。
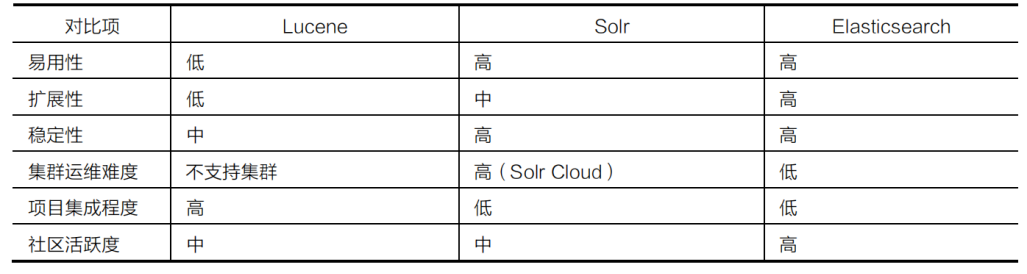
## 数据检索技术框架
 ## 大数据集群安装管理框架
- HDP: 全称是 Hortonworks Data Platform。它由 Hortonworks 公司基于 Apache Hadoop 进行了封装,借助于 Ambari 工具提供界面化安装和管理,并且集成了大数据中的常见组件, 可以提供一站式集群管理。HDP 属于开源版免费大数据平台,没有提供商业化服务;
## 大数据集群安装管理框架
- HDP: 全称是 Hortonworks Data Platform。它由 Hortonworks 公司基于 Apache Hadoop 进行了封装,借助于 Ambari 工具提供界面化安装和管理,并且集成了大数据中的常见组件, 可以提供一站式集群管理。HDP 属于开源版免费大数据平台,没有提供商业化服务;
-
CDH: 全称是 Cloudera Distribution Including Apache Hadoop。它由 Cloudera 公司基于 Apache Hadoop 进行了商业化,借助于 Cloudera Manager 工具提供界面化安装和管理,并且集成了大数据中的常见组件,可以提供一站式集群管理。CDH 属于商业化收费大 数据平台,默认可以试用 30 天。之后,如果想继续使用高级功能及商业化服务,则需要付费购买授权,如果只使用基础功能,则可以继续免费使用;
-
CDP: Cloudera 公司在 2018 年 10 月份收购了 Hortonworks,之后推出了新一代的大数据平台产品 CDP(Cloudera Data Center)。CDP 的版本号延续了之前 CDH 的版本号。从 7.0 版本开始, CDP 支持 Private Cloud(私有云)和 Hybrid Cloud(混合云)。CDP 将 HDP 和 CDH 中比较优秀的组件进行了整合,并且增加了一些新的组件。